Imagine big data flowing in your system. Reviews, articles, blogs, comments, logfiles… day by day, unpredictable quality. And you there in the middle trying to solve:
- Is Dave Smith in review the same as David Smith in article?
- Is Davod R. Smith the same as Daivd Robert Smyth?
- Could it be Davod Snoth in comment is the same as Davidd Smith in review? (notice I and O, N and M near on the keyboard)
- Is Professor David Robert Smith-Smithsson in one article the same as David R. Smyth in another article?
- Could it be Dvae Smitt is the same as David Smith?
- Is Dav1d R0berl 5mith (it might be OCR output) the same as Daivd R. Smith?
- Is Daid Smith the same as Davids Smits (latvian article)?
- Is his job address Kr Barona street 117 the same as 117, Krisjana Barona street?
Scientists have worked quite hard to give a helppful hand, and I will briefly overview some of string similarity measurements and methods because I think it is nice to know that no magic – pure logic.
One blog post earlier I invested a time to teach myself and you, dear readers, to calculate EDIT DISTANCE. It was worth it because the next measure I will discuss about, is Needleman-Wunsch Measure developed by Saul B. Needleman and Christian D. Wunsch in 1970.
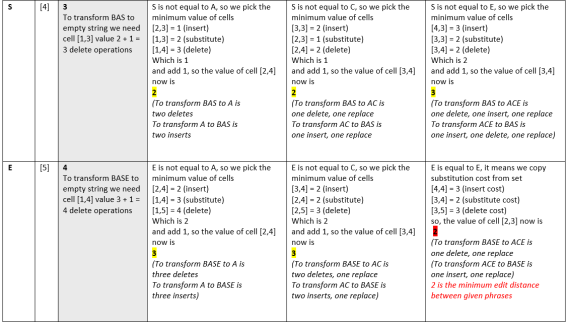
I will remind that in EDIT DISTANCE or LEVENSTEIN distance case we had a tangible result: resulting number was count of insert/delete/substitute operations needed to transform one string to another.
Here are two strings. We, humans, might think it is a high change the object is the same – David Smith. When we see EDIT DISTANCE value 8 for 14 symbols long string, it signalizes that the strings are not similar – and technically they definitely are not:

https://andrew.hedges.name/experiments/levenshtein/
Similarity measure is 1-8/max(14,18) = 1-8/18 = 0.55 – we have to have really loose boundaries to consider these strings similar using Levenstein distance :)
Let’s have a look what some other scientists have done!
Needleman-Wunsch measure you will hear mostly within biology context, comparing DNA sequences. I will make its explanation more human centred, using words.
Needleman-Wunch measure is mathematically proven to find the fewest number of mutations of two sequences, identifying matching parts and the changes needed to transfer one sequence into the other.
Please note that now we will talk about the measure. This is not tangible count of neither I/D/S operations, nor parrots, symbols or atoms. The benefit of using a measure is ability to compare. We will use the same method of comparison to different strings and will use this output measure to evaluate bad-good-better-best matching strings.
I will give also lot of examples not to just another theoretical blablabla. I can’t thank enough this site: http://experiments.mostafa.io/public/needleman-wunsch/
Usually you’ll use samples from biology like TCGAC and TCATA but I’ll use words. Let’s have a look using the same PICADILLA and CROCODILE.
The basic idea within Needleman-Wunsch measure is advanced scoring system which is used in calculation rules:
- match score. If letters match, we assign them a matching score, usually defaulted as is 1, Thus we will reward the match of symbols – we will increase their rating
- mismatch score. If letters don’t match, mismatch score is usually defaulted as -1. Thus we will punish the mismatch of symbols – we will decrease their rating
- gap penalty. The gap score or gap penalty is usually defaulted as -1. Thus we will define, what is preferred: a gap (empty space) or a mismatch (another symbol).
Let’s start with the defaults for scores in our example – I’ll change them later and show you the impact:
- match score 1 (you see, that I like match the most)
- mismatch score -1
- gap penalty -1 (you see, I have set them equal – I don’t care, is it a gap or a mismatch)
The idea of dynamic calculation of Needleman-Wunch measure is similar to EDIT DISTANCE, just prepare a matrix with both strings and follow predefined (slightly different from edit distance) rules and take the maximum (in Edit distance we took the minimum) value from one of left, diag, up.

In addition to EDIT DISTANCE, we must set initial values in matrix – add gap penalties, see the grey line and column.

To calculate the first cell, the green :
- add the gap penalty to upper cell value
- add the gap penalty to left cell value
- in diagonal, we must use match and mismatch parameters
- If letters do not match, add the mismatch score to the diag value
- If letters match, add the match score to the diag value
- When doing that, also put a note, from which cell the final value was taken as max from three. If we can take value from more than one cell, mark them all.
Fill the empty row and empty column (initialize the matrix), only after it we can do the crosses.
Well, you saw the idea, now let’s have the whole matrix done (I am using http://experiments.mostafa.io/public/needleman-wunsch/):

Now, what the result means? As we have defined, we consider mismatch score to be the same as gap score and we see that the result is calculated to have the strings aligned in the best optimal way: there are
- two gaps -O, A-
- four mismatches P-C, I-R, A-O, L-E
- four matches C-C, D-D, I-I, L-L
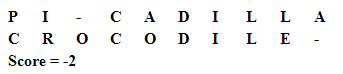
What happens if we change the scoring system? Let’s switch that
I prefer gap over mismatch:
- match score 1 (you see, I still like match the most)
- mismatch score -2
- gap penalty -1 (you see, I now prefer gap better than a mismatch)

Here you the impact when I consider gap is better than mismatch:
- ten gaps
- no mismatches – because we prefer gaps!
- four matches

Let’s continue playing with the scoring system. Let’s set that
I don’t care for gaps and they are as nice as matches:
- match score 1 (you see, I still like match)
- mismatch score -1 (I still don’t like mismatch)
- gap penalty 1 (hehe)
and – voila! – algorithm used in that webpage just gapped all the symbols because I set in scoring system I don’t care for gaps.
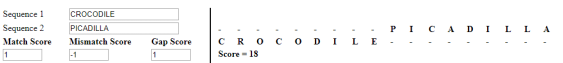
Let’s go further! Let’s penalize gaps very hard.
I really do not like gaps
- match score 1 (I still like match)
- mismatch score -1 (I still don’t like mismatch)
- gap penalty -4 (so I think gap is a very, very bad)
And look, we have strings aligned and there are no gaps at all because I have scored that mismatch is better than the gap.

Let’s have a look on our professors now.
Default scores:
Gap is equally bad as mismatch

Ha, the Needleman-Wunch measure result is better than

Gap is better than mismatch:

Still better than

I really do not like gaps

Heh, professors are much worse because I have no chance to avoid gaps and are having these penalties.

Here I will note that from the table with arrows we can track back alignment path, and, when we have two arrows, from algorithm point of view any path is OK. For example

Notice the score is still the same but alignment differs. Calculation result is the same, either we choose replace E and gap D or gap E and replace D. If you see calculators in web pages where only one result is shown it means their programmers have voluntarily built in additional logic, preferring something.
Needleman – Wunsch algorithm is neutral. Programmers are not.

Now some bonus to Needleman – Wunch measure: we may add
additional scoring matrix to reward similar symbols like O and 0.
You may notice, the letters I and O are near on the keyboard, also letter O is similar to number 0, and lowest letter l is similar to I. We may define that mismatches (I and O) and (O and 0) and (L and I) are not the same bad as, eg, (A and M) mismatch. This is done by adding one more scoring lookup table for mismatch score like

here I have set that I do not penalise I and O, O and 0, L and I mismatches at all, and penalty is bigger for A and M mismatch. In this way you will easily find out that
- Davod and David
- Dav0d and Davod
- AIA and ALA (aIa and ala)
are very similar.
As you see, I haven’t added that Dav0d and David are very similar – then I must add one more mismatch value. Now I will not penalise also I and 0 mismatches. As 0 and 0, I give them higher score because I still prefer the real match over my pseudo matches.

Hmm, I think I also should add 1 and l mismatch not to be penalized. Then I might decide also 5 and S, 6 and G and so on – it depends on my software, my data and my business.
Got the idea?
See the example now.
Let’s compare DAVOD1 with DAVIDL.
I drafted an additional MISMATCH matrix where I define some exceptions to default mistach score. I will consider
- O and 0 the same score as match, L and 1 as match
- I and O (they are near on keyboard), I and L, I and 1 near as match

Here is the my refined result according to my additional score matrix – Needleman-Wunsch measure is 11

And here it would look like if only defaults used – the Needleman-Wunsch measure is 6.
You see my refined result is considered significantly more similar (max possible would be value of 12 and my refined result had 11)

See you in next posts, there are a lot of similarity measures yet.
Disclaimer
This blog is solely my personal reflections.
Any link I share and any piece I write is my interpretation and may be my added value by googling to understand the topic better.
This is neither a formal review nor requested feedback and not a complete study material.